Build a reliable RAG pipeline in n8n with this practical guide. Learn how a RAG pipeline in n8n improves grounded AI workflows.
Building AI systems that actually understand your internal data is harder than it sounds. Even the most advanced language models struggle when context is missing or outdated. As a result, teams face inaccurate answers, repeated manual fixes, and growing technical debt. This is exactly where a RAG pipeline changes the game.
In this guide, you’ll learn how to design a reliable RAG pipeline in n8n without juggling scripts, fragile services, or endless configuration files. More importantly, you’ll see how n8n keeps the process flexible while remaining production-ready.
Why Modern AI Needs a RAG Pipeline
Large language models work well with public knowledge, yet they fall short when questions rely on private or frequently changing information. For example, internal documentation, support tickets, or policy updates rarely exist in a model’s training data.
A RAG pipeline solves this gap by fetching relevant documents at query time and injecting them directly into the model’s prompt. As a result, responses stay grounded in real, trusted sources rather than guesswork.
What Is a RAG Pipeline?
A RAG pipeline combines two ideas: retrieval and generation. Instead of expecting the model to remember everything, the system retrieves useful context first and then generates an answer based on that material.
When you build a RAG pipeline in n8n, these steps live inside a single visual workflow. This structure reduces hidden complexity and keeps every stage visible, traceable, and easy to adjust.
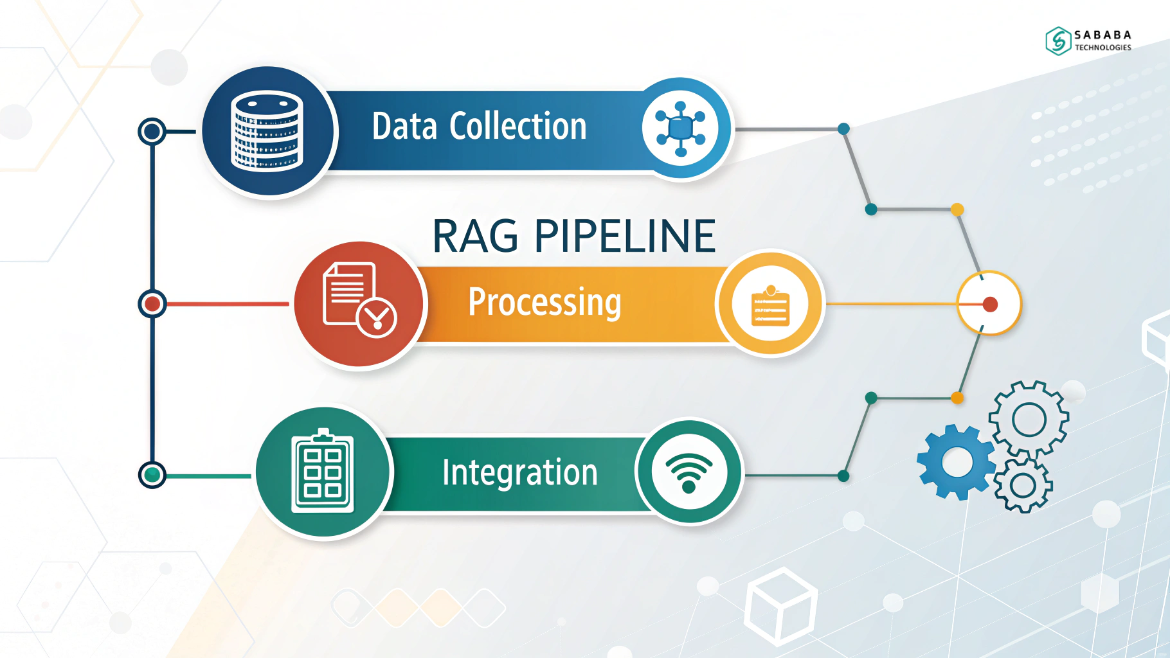
Key Stages of a RAG Pipeline in n8n
1. Data Ingestion
Every RAG pipeline in n8n begins with data ingestion. This stage defines what the AI can access. Typical sources include PDFs, Google Drive documents, Notion pages, or internal knowledge bases.
Documents are loaded, cleaned, and prepared for further processing. Instead of writing custom scripts, n8n handles this with ready-made nodes.
2. Chunking and Embeddings
Next, long documents are broken into smaller chunks. This step improves precision during retrieval. Each chunk then becomes a vector using an embedding model.
At this point, your RAG pipeline transforms raw text into structured meaning that machines can compare efficiently.
3. Vector Storage
The embeddings are stored in a vector database such as Pinecone or Qdrant. This database acts as long-term memory for your RAG pipeline in n8n, allowing fast similarity searches when users ask questions.
4. Retrieval and Context Injection
When a query arrives, the system converts the question into a vector and searches for the closest matches. The retrieved chunks are then injected into the prompt.
This step ensures the RAG pipeline answers with evidence rather than assumptions.
5. Response Generation
Finally, the language model receives both the user question and the retrieved context. It generates a response that reflects actual data instead of vague patterns.
Because the RAG pipeline in n8n is visual, you can inspect every step and fine-tune results without breaking the system.
Why Build a RAG Pipeline in n8n Instead of Code?
Code-heavy setups offer control, but they also increase maintenance effort. Minor changes often ripple across scripts and services. In contrast, a RAG pipeline in n8n centralizes everything.
You can swap models, change data sources, or adjust chunk sizes without rewriting large portions of logic. As a result, experimentation feels lighter and less risky.
Real-World Use Cases
A well-designed RAG pipeline supports many practical scenarios:
- Internal knowledge assistants for employees
- Customer support chatbots trained on help articles
- Policy or compliance question-answering tools
- Technical documentation search systems
Each example benefits from the same principle: reliable answers grounded in real content.
Benefits and Trade-Offs
A RAG pipeline reduces hallucinations and improves trust. It also allows updates without retraining models. However, performance depends heavily on data quality, chunking strategy, and vector search tuning.
Fortunately, this setup makes these trade-offs visible. You can monitor workflows, test changes, and refine behavior over time.
Best Practices for Long-Term Success
- Keep documents clean and well-structured
- Review chunk sizes regularly
- Secure sensitive embeddings
- Monitor retrieval accuracy
- Iterate based on real user queries
These habits keep your RAG pipeline stable as it scales.
This approach exists because language models alone cannot reliably understand private or evolving knowledge. By combining retrieval with generation, teams gain accuracy without retraining overhead.
Building this system in n8n simplifies the process by replacing scattered scripts with a single visual workflow. You maintain clarity, adaptability, and control while delivering AI responses that truly reflect your data.
FAQs
1. What makes a RAG pipeline different from fine-tuning?
A retrieval-based approach pulls relevant information at query time, while fine-tuning permanently embeds knowledge into the model during training.
2. Do I need coding skills to build a RAG pipeline in n8n?
No. Most steps work through visual workflows, while code remains optional for advanced customization.
3. Which vector databases work best with n8n?
Popular options include Pinecone, Qdrant, and Supabase, all of which integrate well with retrieval-based workflows.
4. Can I run a RAG pipeline locally?
Yes. It can run locally using local models and self-hosted vector stores.
5. How do I reduce latency in a RAG pipeline?
Optimizing chunk size, indexing strategy, and vector search significantly improves response times.
Feeling more like puzzles than solutions? That’s when Sababa steps in.
At Sababa Technologies, we’re not just consultants, we’re your tech-savvy sidekicks. Whether you’re wrestling with CRM chaos, dreaming of seamless automations, or just need a friendly expert to point you in the right direction… we’ve got your back.
Let’s turn your moments into “Aha, that’s genius!”
Chat with our team or shoot us a note at support@sababatechnologies.com. No robots, no jargon, No sales pitches —just real humans, smart solutions and high-fives.
P.S. First coffee’s on us if you mention this blog post!